
Multi-agent work needs a control layer.
More agents only help when the work has boundaries. Without boundaries, agents duplicate effort, make conflicting assumptions, overstate weak evidence, and spread decision-making across too many places.
The protocol prevents that drift.
It keeps the orchestrator accountable, separates roles, chooses the smallest useful workflow, and adds review where trust matters.
The Core Pattern
The repeatable pattern is:
- Start with the work type.
- Route it through Think path or Build path.
- Decide the risk and validation bar.
- Choose the smallest useful persona flow.
- Use Safe Lane when scope, dependency, or trust requires it.
- Use local models only for bounded helper work.
- Keep final judgment centralized.
- Record enough evidence that the work can be reviewed.
That is the system: a practical orchestration layer for spending intelligence where it matters.
The Two Front Doors
My implementation of the protocol is called Pathway 1. The supporting implementation notes and protocol artifacts live in the Pathway Protocol GitHub repo.
It has two short triggers:
Think pathBuild path
Think path is for research, synthesis, decision briefs, executive memos, requirements discovery, meeting analysis, and recommendations.
Build path is for coding, debugging, refactoring, tests, codebase mapping, technical implementation, and local proof-of-concept work.
The phrases are short by design. I do not want to paste a large operating manual every time I start a task. The phrase activates the protocol.
Behind the phrase is the system: an OpenAI GPT/Codex orchestrator, role-specific subagents, safety gates, review passes, model lanes, and a record of what happened.
The orchestrator reads the prompt, identifies the task type, estimates risk, checks source clarity, decides whether Safe Lane is needed, and chooses the model lane and reasoning level for each subtask.
Think Path
Think path is the knowledge-work lane.
A simple Think path task may need only a writer and reviewer: summarize notes, turn source material into a clean update, or extract key decisions.
A harder Think path task needs more structure. If sources conflict, the system preserves the conflict. If the output will drive a decision, it gets stronger review. If the source scope spans repos, folders, or large document sets, exploration happens before analysis.
The review dimensions are:
- accuracy,
- completeness,
- source fidelity,
- decision quality.
The protocol helps identify when a memo becomes an operating decision.
Build Path
Build path is the technical-work lane.
A small Build path task might be a focused bug fix with a targeted test. A larger task might touch shared interfaces, authentication, deployment behavior, data handling, or release readiness.
The review dimensions are:
- correctness,
- security,
- completeness,
- regression.
The system scales with risk. A tiny test fix needs a targeted path. A release-facing auth change should be explored, implemented, validated, and reviewed through the right lenses.
This is where token economics become practical. The goal is to spend strong review where it matters.
Safe Lane
Safe Lane is the guardrail layer.
It has three parts:
- Intake,
- Fanout,
- Review.
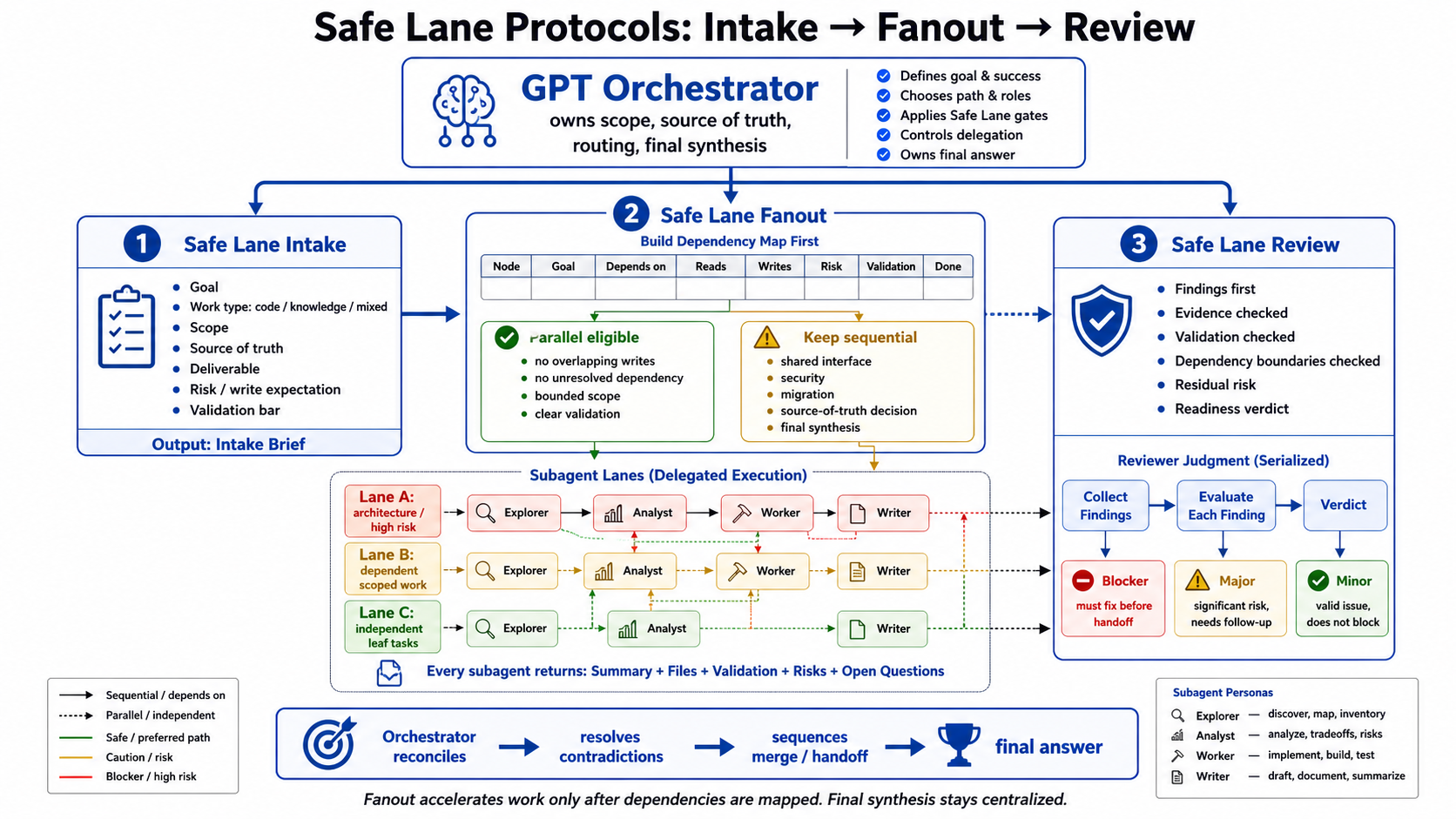
Safe Lane Intake is used when scope, source of truth, deliverable shape, work type, or validation bar is unclear. It turns an ambiguous ask into a bounded brief before work begins.
Safe Lane Fanout is used when the work is large enough to split. It starts only after a dependency map exists. Work stays sequential when two agents would write to the same surface or when the dependency is unclear.
Safe Lane Review is the findings-first trust gate. For code, it checks correctness, regression, security, and validation. For knowledge work, it checks source fidelity, missing coverage, and whether the conclusion is stronger than the evidence supports.
Safe Lane keeps multi-agent work from becoming agent sprawl.
The Dependency Map
Fanout starts with a map.
For each node, the orchestrator needs to know:
- goal,
- dependencies,
- reads,
- writes,
- risk,
- validation,
- done condition.
A node is eligible for parallel work only when it has bounded scope, clean dependencies, no overlapping writes, clear validation, and a reviewable artifact to return.
If that is missing, the work stays sequential.
Handoff Rules
Every delegated task needs a clear contract:
- exact goal,
- bounded scope,
- source of truth,
- reads,
- writes,
- expected artifact,
- validation command or reviewable proof,
- done condition.
Every subagent returns:
- summary,
- files or sources touched,
- validation,
- risks,
- open questions.
The orchestrator reconciles the work, resolves contradictions, decides sequencing, and owns the final answer.
Subagents do not synthesize the whole initiative independently.
Local Qwen As A Helper Lane
Local Qwen fits into this system as a helper lane.
The public abstraction is straightforward:
- it is a local open-weight helper model,
- it runs behind a local endpoint,
- it is used only for bounded first-pass work,
- it can help as explorer, analyst, or first-pass writer,
- it cannot be orchestrator, worker, reviewer, or final authority,
- GPT/Codex reviews every handoff.
Local models can reduce first-pass burden while keeping judgment in the main system. Qwen can help map a document set, extract open questions, draft tradeoffs, or outline implementation slices. Decision work, release judgment, security conclusions, and final user-facing answers return to GPT/Codex.
| Role | Qwen allowed? | Boundary |
|---|---|---|
| Explorer | Yes | Source maps, file maps, architecture sketches, document inventory |
| Analyst | Yes | First-pass tradeoffs, risks, criteria, implementation slices |
| Writer | Limited | First-pass outlines and drafts from supplied evidence |
| Orchestrator | No | Scope, source of truth, routing, final synthesis |
| Worker | No | File edits, implementation, git actions, system changes |
| Reviewer | No | Correctness, security, source fidelity, readiness verdicts |
Every substantive local-model handoff should be classified:
| Classification | Meaning |
|---|---|
| Accepted | Accurate and useful with no meaningful correction |
| Revised | Useful, but incomplete, source-limited, or needing correction |
| Rejected | Inaccurate, unsupported, off-scope, unsafe, or not useful enough to rely on |
That classification keeps local model use from becoming hidden trust.
Evals And Readiness
The protocol needs validation.
For Pathway, check the routing decision, selected persona flow, Safe Lane gates, Qwen eligibility, artifacts created, validation run, review completed, and residual risks.
For local Qwen, check whether the local server is ready, delegation is on, only allowed roles are used, the handoff has enough source grounding, and GPT accepted, revised, or rejected the result.
The eval loop is:
- Delegate a bounded helper task only when the role is eligible.
- Measure tokens, elapsed time, role, path, task, and runtime behavior.
- Review the handoff against the evidence.
- Classify the result as accepted, revised, or rejected.
- Improve routing, prompts, schemas, or context packaging when failures repeat.
- Re-test before trusting the change.
For evidence-heavy Think path work, the stricter schema should preserve source facts, explicit decisions, open questions, risks, recommendations, and claims that should not be treated as decided.
The target is useful first-pass work that keeps final quality intact. No unsupported person, date, ownership, commitment, decision, or source claim should survive GPT review.
Closing
My current view is that serious AI building needs orchestration.
The useful skill is knowing how to divide work, route judgment, preserve evidence, and use different levels of intelligence while keeping accountability intact.
The strongest model stays responsible. Smaller agents do bounded work. Local models help where they can. Every important answer comes back through review.
Token cost was the pressure.
Orchestration became the answer.