
Multi-agent orchestration is partly a token economics pattern.
The core idea is simple: use the strongest intelligence where judgment matters, and route lower-risk work through bounded roles that still come back for review.
Token cost shows up in concrete ways: rate limits, token caps, included usage running out, and higher subscription tiers. It also shows up when every part of a workflow uses a frontier model, large context, and high reasoning by default.
The expensive pattern is asking one strong model to carry every part of the work at one level of intelligence.
A better pattern treats work as a set of roles. Some tasks need final-authority reasoning. Others need careful first-pass inventory, comparison, outlining, or source mapping. Those tasks still need review, but they do not always need the most expensive lane first.
For a solo builder, the question becomes:
How do I keep using the best intelligence available while reserving the most expensive model and highest reasoning level for the tasks that need them?
The Principle
Use the most capable intelligence available, but only where the task actually needs it.
I still want frontier models for hard synthesis, final judgment, risky coding decisions, security review, and important recommendations. I want the strongest reasoning model anywhere being wrong costs more than the tokens.
Many parts of a workflow need care before they need final-authority intelligence. Source mapping, open-question extraction, rough outlines, likely-file identification, and first-pass comparison can run in a different lane.
That is the practical meaning of “just enough intelligence.”
From Prompting To Orchestration
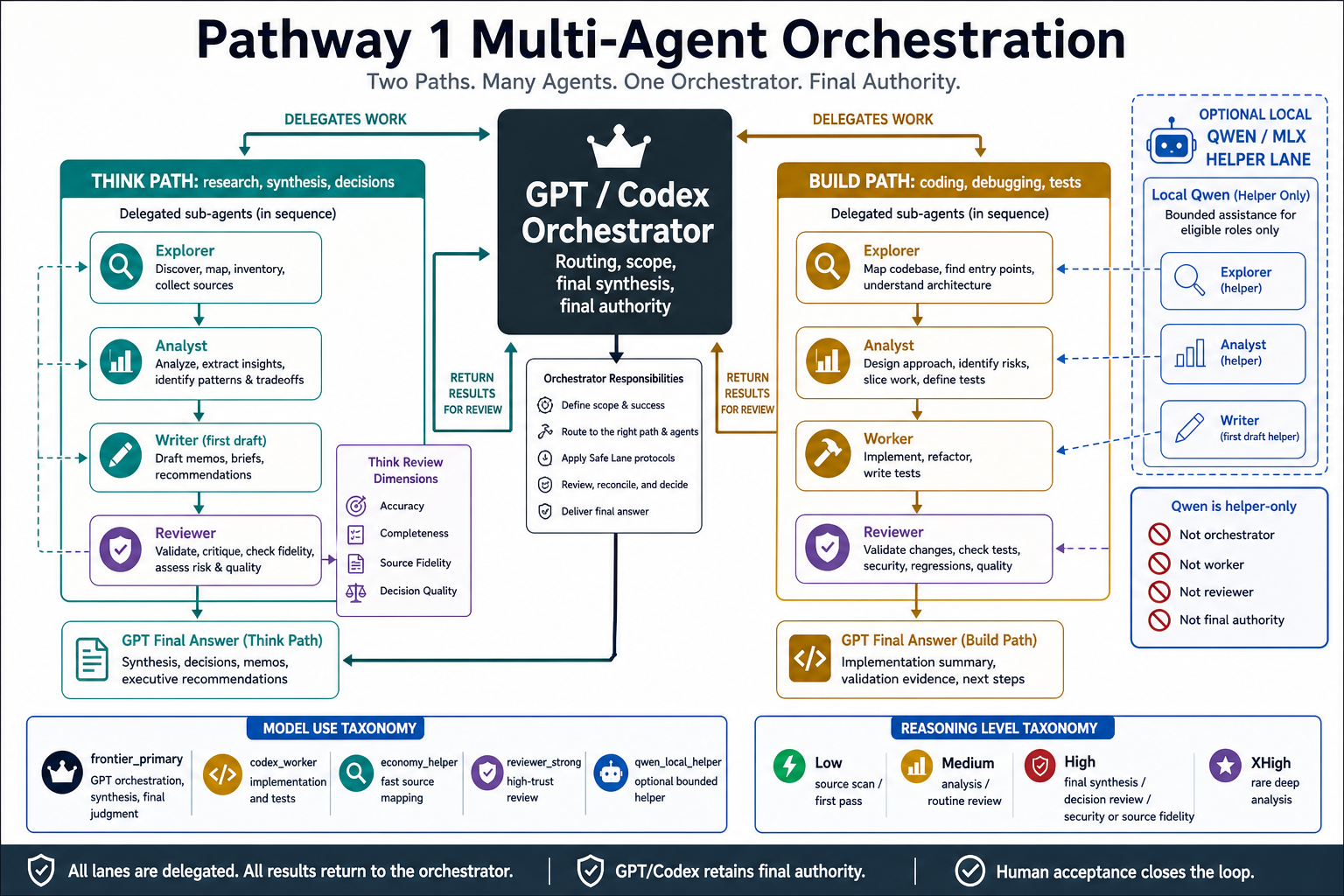
The shift is moving from “ask the model to do the thing” to “route the work through a controlled system.”
At the high level, the system needs four parts:
- an orchestrator that owns scope, routing, final synthesis, and final authority,
- role specialists that handle bounded subtasks,
- model lanes that match task difficulty and cost,
- review gates that decide when output is ready to trust.
The supporting implementation notes and protocol artifacts live in the Pathway Protocol GitHub repo.
The orchestrator breaks the request into smaller jobs, sends those jobs to helper agents, and pulls their results back into one answer. An explorer maps files or sources. An analyst identifies tradeoffs. A writer drafts. A worker builds or tests. A reviewer checks readiness.
The orchestrator also decides which model lane and reasoning level each part of the work deserves. A low-risk source map needs a smaller model and reasoning budget than a security review, final recommendation, or release decision.
The Tuned Team
The tuned team is intentionally small.
The core roles are:
orchestrator: routes the work and owns final synthesis,explorer: maps files, sources, documents, entry points, and unknowns,analyst: turns evidence into options, risks, tradeoffs, criteria, and implementation slices,worker: makes bounded technical changes after scope is clear,writer: drafts human-facing artifacts from evidence,reviewer: checks readiness before trust.
Some work needs specialized review: security, regression, source fidelity, or decision quality.
The value is separation. Each role has a bounded job, and final judgment stays centralized.
Local Models Fit, But Carefully
Local models add another lane.
I treat local models as helper lanes, not final authority. In my setup, local Qwen can help with bounded first-pass roles: explorer, analyst, and limited first-pass writer.
Final authority stays out of the local lane:
- orchestration,
- implementation,
- review,
- security decisions,
- final user-facing conclusions.
That boundary makes the local model useful without turning it into hidden trust. Qwen can map sources, outline options, draft tradeoffs, or summarize supplied evidence. GPT/Codex reviews the handoff and classifies it as accepted, revised, or rejected.
Model Use Becomes A Taxonomy
The architecture asks five practical questions before routing work:
- What kind of subtask is this?
- How much reasoning does it need?
- What is the risk of being wrong?
- Does the output need final review?
- Is this safe for a local helper model?
Those questions lead to model lanes:
| Lane | Used for | Not used for | Review requirement |
|---|---|---|---|
| Frontier primary | Orchestration, hard synthesis, complex coding decisions, final judgment | Routine source scanning or low-risk first drafts | Owns or performs final review |
| Coding worker | Implementation, tests, debugging, refactoring | Final release judgment or broad strategy decisions | Reviewed before trust |
| Strong reviewer | Correctness, security, regression, source fidelity, readiness checks | First-pass drafting or bulk exploration | Findings reconciled by orchestrator |
| Economy helper | Low-risk exploration, source mapping, quick comparison | High-stakes conclusions or final authority | Spot-checked or risk-reviewed |
| Local helper model | Bounded first-pass source mapping, tradeoffs, outlines, summaries | Orchestration, implementation, review, security, final conclusions | GPT/Codex accepts, revises, or rejects |
The same logic applies to reasoning levels. Use low reasoning for obvious classification and source scanning. Use medium for normal analysis and routine coding. Use high for hard decisions, source fidelity, security, and important recommendations. Reserve extra high reasoning for rare work where uncertainty, stakes, or reversibility justify the cost.
What This Changes
The old mental model was:
Ask a smart model for an answer.
The new mental model is:
Build a routing system for work.
That shift changes the operator’s job. The operator designs the flow of intelligence.
Multi-agent orchestration becomes a cost-control pattern, a quality-control pattern, and a judgment-preservation pattern at the same time.
A tuned team of agents is useful only when the work stays bounded, the handoffs stay reviewable, and final judgment stays centralized.
That is where the protocol matters.